
Last Updated on: October 16, 2025
When it comes to understanding visitor behavior on your website or mobile app, user-agent data certainly can provide valuable insights into the technical components of their interactions. However, user-agent data is sometimes parsed differently between systems, causing variation in how that data ends up being displayed in other tools or visualizations.
Some tools use external libraries for parsing, other tools leverage their own functionality, and others have a combination of the two. This difference can lead to discrepancies in reporting, inconsistencies in device analysis, and fluctuations in how user data is reported overall.
This is a key consideration when switching the Amplitude destination in Segment from Amplitude (Classic) to Amplitude (Actions). When making the switch, the user-agent data is parsed differently between systems, resulting in the reporting data suddenly changing how it is displayed.
Key Takeaways
- User-agent data is a string of text that contains information about a client’s software, device, and operating system.
- Parsing user-agent data is necessary to extract relevant information from the user-agent string in a format that is actionable.
- Different tools use different parsing libraries to parse user-agent data, which can lead to discrepancies in reporting and inconsistent device analysis.
- When making the switch from Amplitude (Classic) to Amplitude (Actions), the user-agent data is parsed differently between systems, resulting in changes in how reporting data is displayed.
- Data discrepancies in marketing analytics can cause inaccurate insights, inefficient processes, loss of trust in data, difficulty in integrating data, and inability to segment users.
- It is important for businesses to have systems in place to identify and correct data discrepancies as soon as they occur to ensure the accuracy and reliability of their data.
Contents
What Is the User-Agent?
Let’s start from the top: the user-agent is a string of text that a web browser or other client sends to a web server along with each request for a web page or other resource. This data contains information about the client software and its capabilities, as well as information about the device or operating system the software is running on.
User-agent data is important because it allows website and app owners to understand their users’ browsing environment and optimize their content accordingly. For example, a website owner can use user-agent data to determine whether a user is on a mobile device or a desktop computer and serve a different version of the site accordingly. Additionally, user-agent data can be used to identify and segment users and track their behavior on the website or app.
The user-agent data typically includes the following information:
| Context | Description |
|---|---|
| Browser name and version | The name and version of the browser being used to access the website or app. |
| Operating system | The type and version of the operating system the browser is running on. |
| Device | The type of device being used to access the website or app (e.g. desktop, mobile, tablet). |
| Language | The preferred language of the user’s browser. |
Parsing the Data
The visitor’s user-agent data might come into your system looking something like this:
"Mozilla/5.0 (iPhone; CPU iPhone OS 15_6_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.6.1 Mobile/15E148 Safari/604.1" Not very useful, right?
From its raw form, the user-agent data needs to be parsed to pull out the individual data points and bits of information in a format that is actionable for users. To parse user-agent data, web servers and applications typically use regular expressions or user-agent parsing libraries to extract relevant information from the user-agent string.
If the user-agent data is parsed by two different parsing libraries, the end results might be different from library to library. This means that if you’re reporting on data points that are derived from user-agent strings, the reporting might be inconsistent (or even inaccurate) depending on the parsing libraries used.
You can see where I’m going with this…

Effectively Track Your
Marketing Campaigns & Prove ROI
Regardless of what analytics tool you use, you need to have
an efficient strategy to track your marketing campaigns and reach your ROI goals.
Amplitude Destinations in Segment and User-Agent Parsing
There are two destination types for Amplitude in Segment: one is Amplitude (Classic) and the other is Amplitude (Actions). While there are a variety of differences between the two, the biggest difference related to this particular situation has to do with the way the data is sent from Segment to Amplitude.
In the case of Amplitude (Classic), Segment is loading the Amplitude script in device mode, which means the Segment is loading the Amplitude script on the website and then making the necessary calls in the browser to send the data to Amplitude. This effectively means the data is being sent to Amplitude client-side. Because the data is being sent directly to Amplitude from the browser, it does not pass through Segment’s servers at all and all of the important contextual information is sent to Amplitude accordingly.
Conversely, Amplitude (Actions) does not rely on the on-page script at all, and instead receives all data from Segment in cloud mode, meaning server-side. This means that the contextual information from the browser (which includes the user-agent data) is being sent through Segment’s servers before it gets forwarded to Amplitude. If you are looking for more differences between the Classic and Actions destinations for Segment, check out this breakdown from their support documentation.
So what do the destination types have to do with user-agent parsing?
When the data is sent directly to Amplitude via device mode, Amplitude is responsible for parsing the raw user-agent data from the request, using their own parsing libraries to distill important device-specific information from it.
On the other hand, when requests are sent through Segment’s servers first and then to Amplitude (cloud mode), it’s actually Segment who is doing the user-agent parsing and then forwarding the resulting data points to Amplitude in the event mapping(s).
To make matters even more confusing, Segment is using a parsing library for their server-side destination maintained by – you guessed it – Amplitude. If you want to look under the hood, you can check out the library here: Amplitude Parser on NPMJS.
Why It Matters
If you have two different data sources in Segment and one is using Amplitude (Classic) and the other is using Amplitude (Actions), it might not be a big deal to have the user-agent data parsed by two different libraries. You can just report on it in Amplitude the same way you would normally and you likely won’t notice the difference.
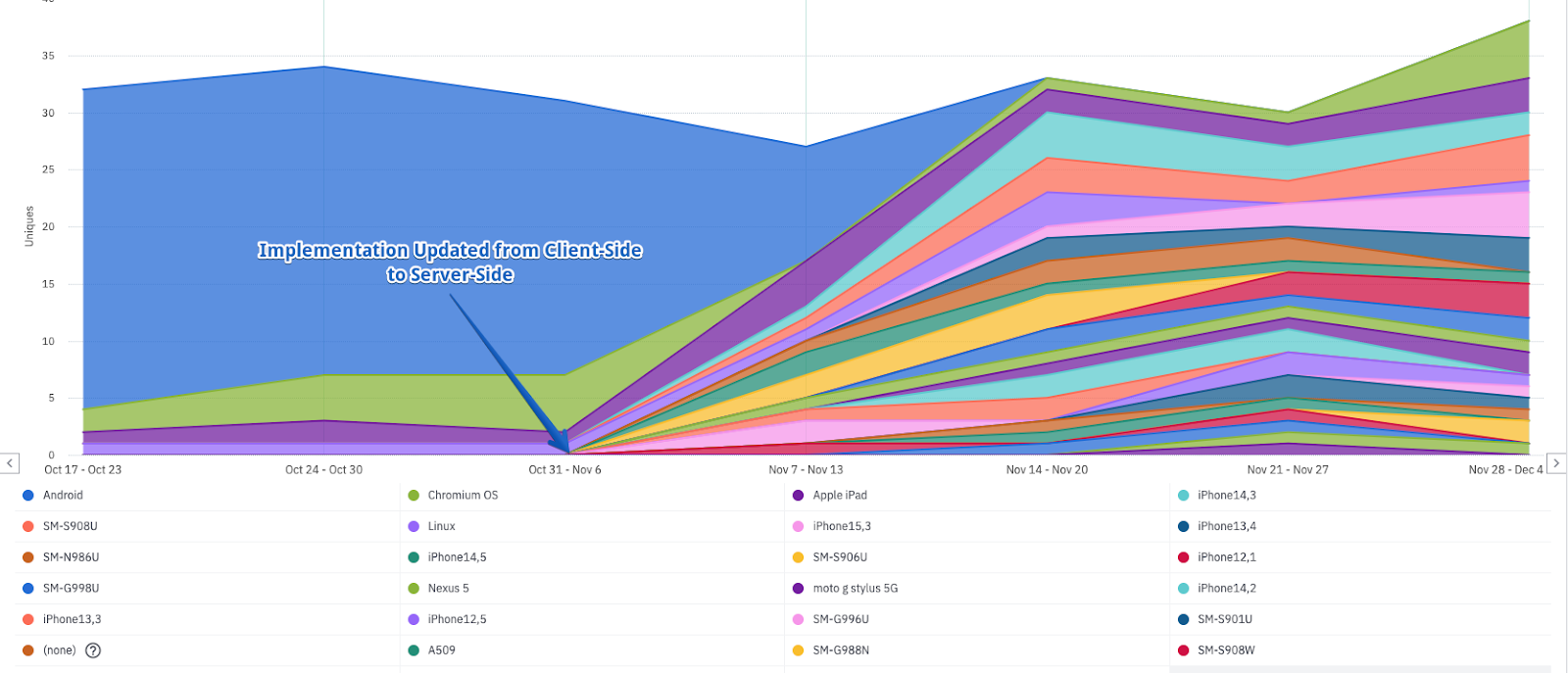
However, if you have a single data source in Segment that is using Amplitude (Classic) and you switch that destination to Amplitude (Actions), you will notice your reporting will suddenly change the way it displays device family breakdowns, operating system classifications, and other details.
This means that you will see a noticeable change in visualizations that report on this information which could lead to inaccurate insights, confusion amongst other team members, and more.
In general, data discrepancies in marketing analytics can cause a number of problems for businesses, such as:
- Inaccurate insights: If data discrepancies are not identified and corrected, they can lead to inaccurate insights and conclusions. This can result in businesses making decisions based on false information, which can lead to wasted resources, lost revenue, and a decrease in customer satisfaction.
- Inefficient processes: Data discrepancies can also lead to inefficiency in business processes. For example, if data is not consistent across different systems and tools, it can cause delays and errors in data analysis, reporting, and decision-making.
- Loss of trust in data: Data discrepancies can also erode trust in data and analytics within an organization. When stakeholders see inconsistent data, they may question the accuracy and reliability of the data and be less likely to trust the insights and recommendations that are generated from it.
- Difficulty in integrating data: Data discrepancies can make it difficult to integrate data from different sources and tools. This can lead to a lack of cohesion and a lack of a single source of truth, making it difficult to get a clear picture of customer behavior and make data-driven decisions.
- Inability to segment users: Data discrepancies can also make it difficult to segment users and perform personalized marketing. Without accurate user-level data, businesses cannot identify and target specific segments of their customer base.
Final Thoughts
Overall, data discrepancies can have a significant impact on a business’s ability to make data-driven decisions and optimize its marketing efforts. It’s important for businesses to have systems in place to identify and correct data discrepancies as soon as they occur, in order to ensure the accuracy and reliability of their data.
Any [Marketing|Revenue|Dev] Ops professionals know full well that even the smallest change (like how the user-agent data is parsed) can have a snowball effect on how that information ends up being displayed and analyzed in other downstream tools like Amplitude. While oftentimes there’s not a ton you can do to control it – particularly the libraries different tools use to parse raw request data – it’s still a good thing to keep in mind when making any changes.
Effectively Track Your
Marketing Campaigns & Prove ROI
Regardless of what analytics tool you use, you need to have
an efficient strategy to track your marketing campaigns and reach your ROI goals.

Leave a Reply