Key Takeaways
- Operationalizing data through the reverse ETL process enables real-time decision-making, increased collaboration between departments, and streamlined workflows.
- Reverse ETL can help business users get the data they need without relying on engineering resources, making it easier for analysts to focus on high-level tasks.
- Dedicated reverse ETL tools are generally more powerful and cost-effective than iPaaS and open-source solutions.
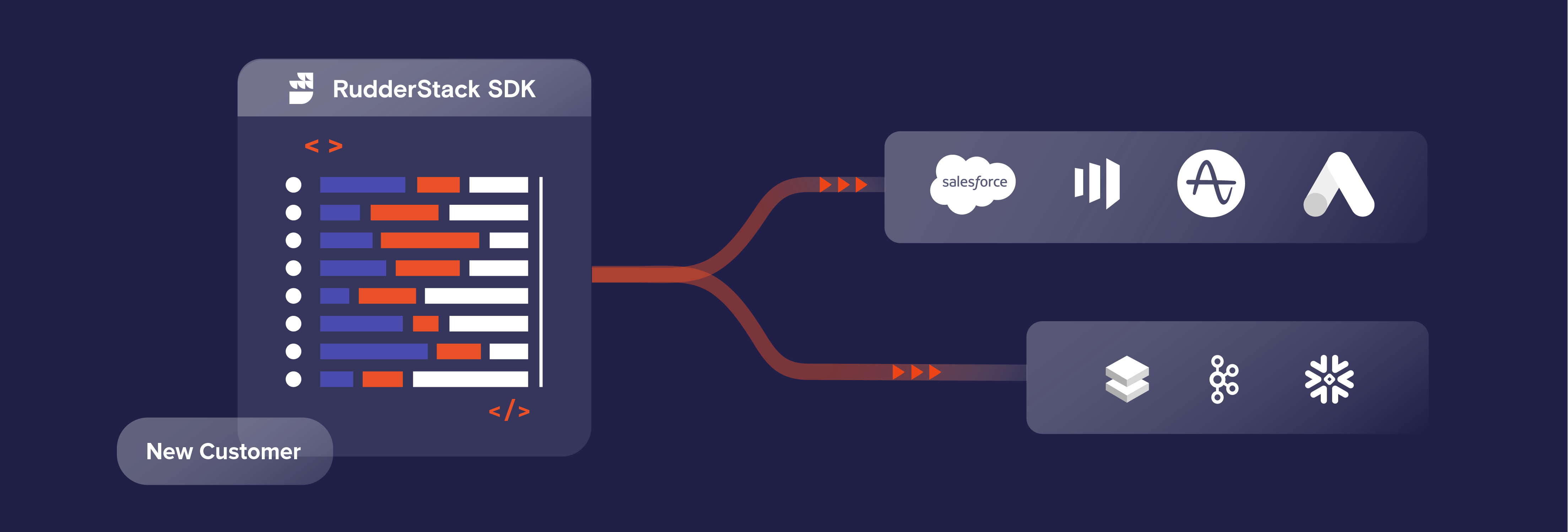
Reverse ETL enables any team, from sales to product, to access the data they need within the systems they use.
The significance of this cannot be understated. Too often, data is siloed within different departments leading to inefficiencies, decision-making based on sub-optimal information, and even a general feeling of powerlessness. Reverse ETL makes data easily accessible to everyone who needs it.
This isn’t to say that reverse ETL is perfect. Your data architecture will always have anomalies and vulnerabilities, but reverse ETL is a compelling process with many benefits.
What Is Reverse ETL?
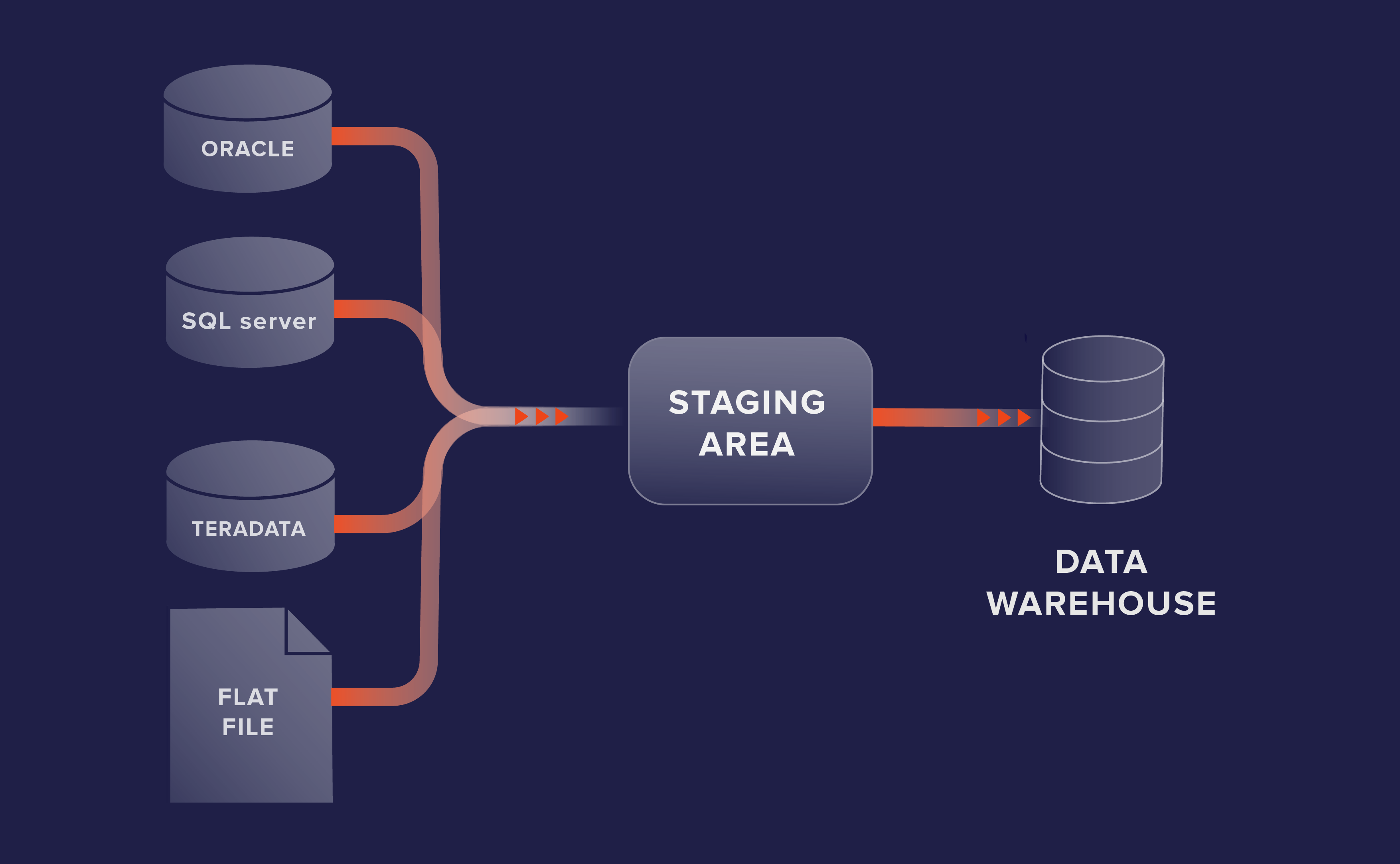
ETL, ELT, and reverse ETL are data pipelines that move data from one system to another.
“E” is for “extract,” taking data out of the source system. “T” is for “transform,” changing the data to fit the destination system (this is also where data cleansing and other data preparation activities occur.) “L” is for “load,” which puts data into a new database.
Reverse ETL takes data from a data warehouse or data lake and prepares it for use in operational systems.
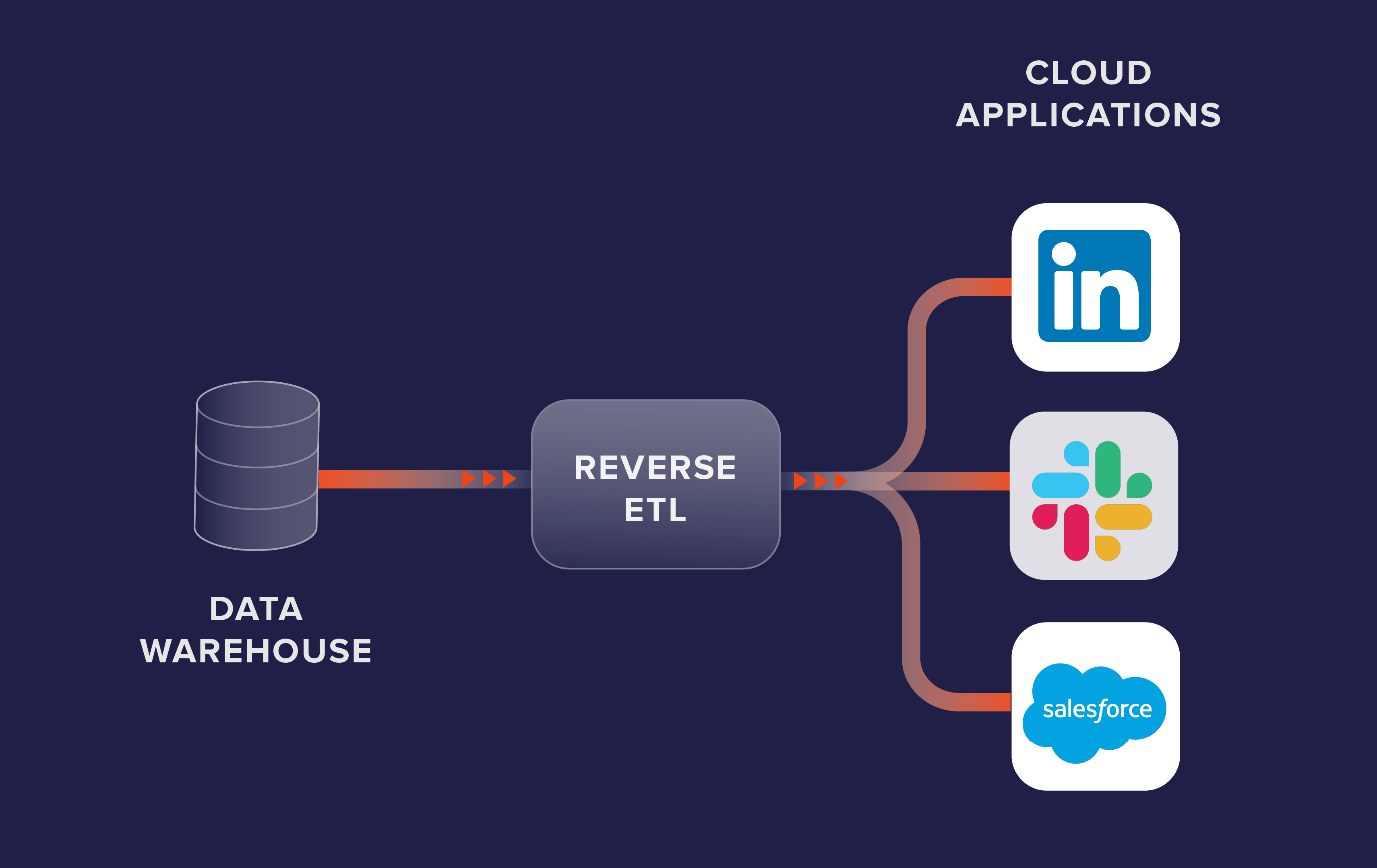
Reverse ETL is the opposite of the ETL process, which takes data from operational systems, cleans and structures it, and loads it into a data warehouse.
ETL is typically used for batch-oriented data integration, while reverse ETL is usually used for real-time data activation. In other words, ETL focuses on integrating data from multiple sources, and reverse ETL is focused on making data available for consumption.
ELT is slightly different from ETL and reverse ETL in that it loads data into a destination database and then performs the transformation within that database. ELT has become more common in recent years as data warehouses and data lakes have become more powerful.
It’s important to note that while ETL terminology helps clarify data pipelines, try not to get too caught up in the labels. Any good data architecture should prioritize robust and flexible data flows that can capture and operationalize data regardless of going upstream or downstream—irrespective of the labels.
The Main Reason Businesses Want to Implement Reverse ETL
Product and data teams are endlessly working towards making data more accessible, democratized, and reliable—which raises the question: what’s the value of data?
The proposition for reverse ETL is simple: it enables different departments like product, marketing, sales, engineering, and customer support to be more self-sufficient and effective by giving them direct access to the data they need within the tools they use.
By activating or operationalizing data, reverse ETL paves the way for real-time decision-making, increased collaboration between departments, and streamlined workflows.
Additionally, reverse ETL can help reduce the burden on data analysts by making it easier for business users to get the data they need without relying on engineering resources. Translation: no more emailing CSV files and reports across departments to get a 360-degree view of your customer.
Consider a common scenario: You want to increase customer retention. You have an array of data about customers stored in your warehouse—including purchase history, customer service interactions, and web browsing events.
With reverse ETL, you can take this data and make it available in your customer communication software. So when a customer contacts support, the agent will have all the relevant information at their fingertips and can proactively offer solutions to keep the customer from churning.
Without reverse ETL, data outside of the agents’ primary software would be siloed in the warehouse collecting dust, and you’d miss out on an opportunity to increase customer retention.
There are many other examples of how reverse ETL can operationalize data, including:
- Increase sales by making data about potential customers available in your CRM.
- Reduce fraud by surfacing data about suspicious in security and fraud detection systems.
- Optimize marketing campaigns through real-time feedback on customer behavior.
- Improve product engagement by consolidating data from your experiments in your analytics tool.
- Improve supply chain management by making data about inventory levels and supplier performance available in enterprise resource planning (ERP) systems.
Even if you increase your results by half a percentage point in any of these areas, reverse ETL can significantly impact your bottom line.
4 Ways Businesses Use Reverse ETL
We’ve established that reverse ETL enables business units to be more self-sufficient and effective by giving them direct access to the data they need within the tools they use. But how does this work in practice?
There are four use cases for reverse ETL that are prevalent among businesses:
1. Data Activation
As we’ve established, data activation is about making data available and accessible to people who need it when needed. You can leverage reverse ETL to activate data in several ways, including:
- Building custom dashboards and reports tailored to specific roles or departments.
- Setting up alerts to notify people when something important happens.
- Integrating data into existing workflows.
- Enabling self-service access to data so people can get the answers they need without relying on your employees.
Data activation is the primary use case for reverse ETL, as it’s the best way to operationalize data and make it actionable.
2. Data Enrichment
Data enrichment can take many forms, such as adding missing values or filling gaps in your records. For example, if you have a list of customer addresses but are missing ZIP codes, you can use reverse ETL to look up the missing data and complete your records.
By enriching your records, you can get a more complete view of your data and make better business decisions.
3. Data Transformation
Data transformation is about taking your data and making it usable for different purposes. This can involve aggregating data from multiple sources, pivoting data to change the perspective or even just cleansing records to remove inaccuracies.
For instance, you can combine data transformations with the Reverse ETL process to make data from a legacy system compatible with a new system. Another big use case is anonymizing data for privacy compliance.
4. Data Quality
Reverse ETL can also improve the quality of your data. By replicating records from your warehouse into business apps, you can catch errors and inconsistencies in near-real-time and fix them before they cause problems.
For example, if you have duplicate records in your database, a reverse ETL pipeline can help you identify and remove them automatically.
Reverse ETL Tools: Integrations + Workflows for the Modern MarTech Stack
The modern tech stack involves extracting and loading source data like events from marketing analytics and social media platforms, transforming the data in your warehouse before activating it in operational systems.
You need reliable tools at each stage of this process to get accurate real-time data for your business units. Let’s break this down, starting with extraction/load tools.
Phase 1: Extracting & Loading
In the first step, you’re extracting data from shopping carts, analytics, social media engagement, or any significant event related to your marketing activities and loading that into your data warehouse. This process requires a conventional ELT tool.
With RudderStack Extract, you can collect your events and data from different sources, such as Facebook Ads, Google Analytics, Marketo, HubSpot, Stripe, and more. Then you can send them to your data warehouse for transformation.
Phase 2: Transforming
At this point, you’ve used an ELT to extract source data and pipe it into your warehouse. In this phase, you need two tools; a data warehouse like Snowflake and a data transformation tool like dbt, or RudderStack.
Your data warehouse will serve as a single source of truth for all your marketing data. Here you’ll transform, aggregate, and prepare data for activation. dbt is an open-source tool that makes it easy to write SQL and transform data in your warehouse.
dbt also offers many features to help you manage your transformation process, including:
- Track which transformations have been run and when.
- Schedule transformation tasks.
- Share transformation logic across projects.
- Manage dependencies between transformations.
Phase 3: Activating
In the final phase, you need to activate your data so the teams in your company can use it. Reverse ETL tools are designed to move data from your warehouse into operational systems.
Rudderstack offers features to help you manage your Reverse ETL process include:
- A visual interface to map data from your warehouse fields to operational systems
- Providing pre-built connectors to hundreds of destinations
- Automating data processes on a time schedule or through API triggers
Reverse ETL tools are the opposite of ELT tools, as they’re specifically designed to move data from your warehouse into operational systems.
With reverse ETL tools, you can push data into more systems, getting better use out of your data. Moreover, reverse ETL tools provide a visual interface to choose which query output columns are used to populate standard and custom fields in your operational system.
Other reverse ETL tools include Hightouch and Census.
Data Integration Tool Comparisons and Alternatives
Many data integration tools are available on the market, each with its features and capabilities. Despite having overlapping features, each platform claims to be the best solution for data teams.
Adding to the confusion, some companies have built their own data pipelines using a combination of open-source, in-house, and commercial tools. But with so many great out-of-the-box solutions, we highly recommend against this path.
The best reverse ETL tool for your company depends on many factors, including:
- Data sources (e.g., Salesforce, Hubspot, and Stripe)
- Data destination (e.g., data warehouse and data lake)
- Complexity of data transformation
- Number of reverse ETL jobs
- Team size
- Budget
The standard solutions for data activation are CDPs, iPaaS, and reverse ETL tools. Let’s look at how they stack up.
Reverse ETL vs. CDP
Some reverse ETL/data activation platforms claim you don’t need a CDP in a modern tech stack.
For instance, if you have an ELT tool, a cloud data warehouse, and reverse ELT, what’s the purpose of a CDP? While these tools may have light integrations with each other, there’s no unified strategy to help you build an end-to-end user pipeline.
With a warehouse-first CDP like RudderStack, you’re pulling and pushing data and consolidating the information into optimal profiles within the warehouse for activation.
Say you’re pulling a segment of customers from Iterable that are performing well, and you want to push that data into a production application or direct mail campaign; you can use a CDP to enrich and facilitate that pipeline.
A CDP is a pass-through system that lets you set up automations in real-time. Another example is if someone visits your website. Through your CDP, you can see that they’re a high-value user, so you send them a quick email within 10 minutes with contextual awareness of which pages and features they’re interested in.
The benefit of a CDP like RudderStack is that it does not create another data silo outside the warehouse and has data activation capabilities, which lets you create a reverse ETL pipeline without needing a separate tool.
Reverse ETL vs. iPaaS
An iPaaS (integration platform as a service) is a cloud service that provides pre-built connectors for on-premise and SaaS applications. Popular iPaaS solutions include MuleSoft, Dell Boomi, and Zapier.
An iPaaS is an excellent way to connect a few applications quickly. However, as the number of integrations grows, an iPaaS can become complex and expensive.
An iPaaS isn’t a complete solution for data teams as it lacks many critical features for data warehousing, including:
- No support for SQL or a schema-on-read database.
- No transformation capabilities.
- Limited data modeling.
- Proprietary data storage.
In contrast, reverse ETL tools like RudderStack support SQL and schema-on-read databases like Snowflake and BigQuery.
Reverse ETL also offers a rich set of transformation capabilities with a user-friendly interface that lets you map data fields, set primary and foreign keys, and join tables without writing any code.
Open-Source Alternatives to Reverse ETL
Open-source reverse ETL tools exist; however, most require a lot of coordination with other solutions to make them work.
If you’re looking for an open-source reverse ETL solution, you may want to consider one of the following:
- Apache NiFi: A dataflow management system that can be used for reverse ETL. However, the tool has a limited user interface and requires programming knowledge to set up and maintain pipelines.
- Talend: A popular open-source data integration tool to create a reverse ETL pipeline. Talend offers a graphical user interface and can connect to over 900 (and counting) data sources. That said, Talend is less widely adopted than Apache NiFi and can be challenging to learn.
- Pentaho Data Integration: Another open-source reverse ETL tool that offers a graphical user interface. Pentaho Data Integration is a popular reverse ETL tool but comes with a steep learning curve.
While your data engineering teams can make open-source reverse ETL tools work for your company, it’s essential to consider the time and resources required to set up and maintain these tools.
A reverse ETL solution like RudderStack, which is built for your specific needs, is generally more cost-effective.
Increase Efficiency with Reverse ETL and Useful Data
Reverse ETL can save your company time and money by automating data pipelines and workflows.
RudderStack offers a user-friendly interface, transformation capabilities, and support for SQL and schema-on-read databases. Not to mention the 150+ streaming destinations to sync your data with your entire stack effortlessly.
Take advantage of an all-in-one warehouse-first CDP plus reverse ETL solution to make your data work for you.

Leave a Reply