
Last Updated on: April 28, 2026
Contents
Your warehouse holds some of the most valuable customer data in your business. But for many companies, it only supports reporting. Sometimes it becomes a storage layer where important information sits unused.
If you invest six figures in a warehouse, it shouldn’t be a cost center. It should support revenue.
Reverse ETL closes the activation gap: it automatically sends modeled, trusted data from your warehouse into your revenue stack so teams can act on insights in real time.
Much of your best customer data is trapped in dashboards or summary tables. It never reaches the marketing, sales, and success tools that rely on it. This creates an activation gap: you have the data, but you can’t act on it.
The gap exists because of how data gets into the warehouse. Traditional ETL (Extract, Transform, Load) pulls data from tools like Salesforce, product systems, or marketing platforms and loads it into the warehouse. It’s essential for analytics, but it creates a one-way flow. Data goes in. Nothing comes out.
Reverse ETL changes that. It sends modeled, trusted data from your warehouse into the tools your team uses every day. It turns your warehouse into an operational system that supports segmentation, personalization, sales workflows, lifecycle marketing, and more.
Key Terms
- ETL (Extract, Transform, Load): moves data from tools into the warehouse
- ELT (Extract, Load, Transform): loads raw data first, transforms inside the warehouse
- Reverse ETL: moves modeled data out of the warehouse into operational tools
- CDP (Customer Data Platform): ingests, resolves identity, and syncs customer data , often uses Reverse ETL for activation
What Can You Do With Reverse ETL?
The Reverse ETL market reached $485M in 2024 with a 35% CAGR, driven by enterprises unlocking warehouse data for revenue operations. Most companies lag on activation , here’s what you can do.
Reverse ETL makes warehouse data useful in your revenue stack. Instead of custom pipelines for each tool, you sync clean, modeled data directly into your operational platforms. A few common use cases include:
Audience building: Query the warehouse for precise groups , such as “customers who purchased A but not B” , and send those audiences to advertising or email tools.
Profile enrichment: Sync attributes like LTV, churn risk, product behavior, or support sentiment into your CRM or CDP so teams see a complete customer profile.
Identity control and privacy: Activating data from your own warehouse gives you control over customer identities. This matters in regulated industries, where you can sync audiences without exposing underlying reasons or sensitive attributes.
How Do You Choose the Right Reverse ETL Approach?
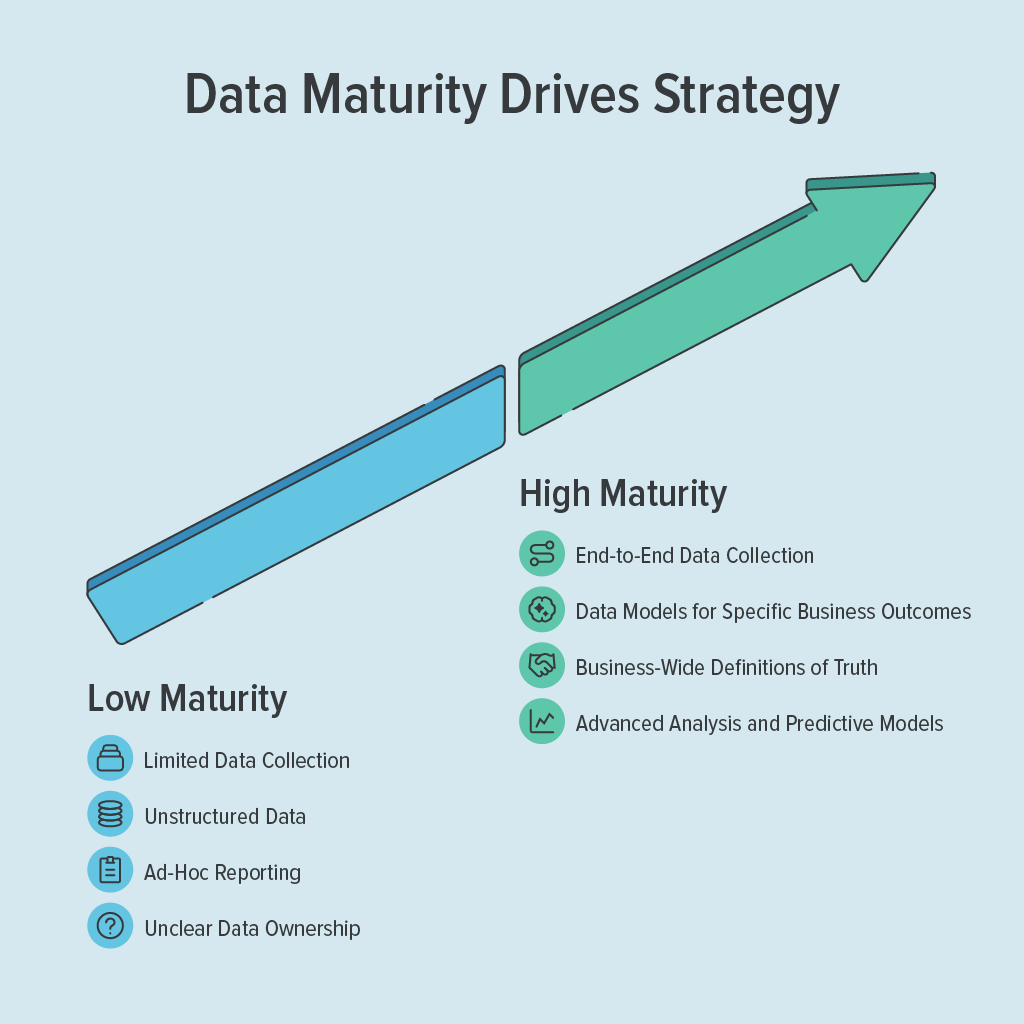
Choosing the right Reverse ETL setup depends on your data maturity , the quality of your warehouse data and your readiness to activate it.
Level 1: Emerging (Months 0–6)
You’re still establishing tracking, naming conventions, and core models. Inconsistent data quality is common. Reverse ETL is not ready here , fix fundamentals first. Activation on bad data creates bad outcomes at scale.
Level 2: Maturing (Months 6–18)
You have standardized event naming, core dimensional models (customers, products, transactions), and a basic data dictionary. You’re ready for pilots. Test one or two high-confidence use cases before expanding.
Level 3: Mature (18+ months)
You have production-grade models with SLAs, comprehensive governance and lineage, and ML-ready datasets. Reverse ETL becomes a multiplier. You can push LTV values, predictive scores, cohort data, and product signals into downstream tools immediately across your lifecycle and revenue programs.
How Do CDPs Support Reverse ETL?
Most modern CDPs now support warehouse-based activation. Depending on your needs, a CDP can help you collect data, resolve identities, and sync modeled attributes to downstream tools. Tools in this category include:
- Hightouch
- RudderStack
- Census
- Segment
There are also multichannel marketing tools that connect directly to warehouses, like Braze or Customer.io. Using the warehouse as the source of truth is sometimes called a “composable CDP.” In practice, it’s just one way to structure your stack. With strong data foundations, you can combine ingestion, identity resolution, and warehouse activation in the configuration that fits your team.
You can read our full perspective on the composable CDP architectural trend here.
What Are the Alternatives to CDPs for Reverse ETL?
CDPs aren’t the only path to warehouse activation. Many operational platforms can pull data directly from warehouses. For example:
- Marketing automation tools like Braze, HubSpot, and Customer.io can import audiences or attributes
- Data orchestration tools like Airbyte or Snowpipe can support technical teams that want full control
- Internal engineering-built pipelines can serve as Reverse ETL when companies prefer in-house ownership
These approaches vary in flexibility. They may not offer the identity resolution or audience management features of a CDP, but they work well for focused use cases. Learn how to evaluate your full MarTech stack architecture here.
Warehouse Platform Impact on Reverse ETL
Your warehouse choice influences Reverse ETL performance and cost:
- Snowflake: Best-in-class integration coverage; most Reverse ETL tools connect natively. Highest compute costs if queries are unoptimized.
- BigQuery: Strong cost efficiency when data is well-partitioned. Slightly fewer native Reverse ETL integrations than Snowflake.
- Redshift: Mature platform, ideal for AWS-native shops. Slower query performance for real-time sync scenarios.
Warehouse choice matters less than execution: query optimization and sync design drive results regardless of platform.
Why Execution Determines Reverse ETL ROI
Reverse ETL only works when the warehouse and downstream tools are prepared to use the data. A few execution factors usually determine success:
Cost control: Warehouse compute, tool fees, and destination charges compound quickly. Budget 20–40% more than your initial estimate.
Real example: One B2B SaaS client synced customer attributes to their CRM every 5 minutes. The sync was expensive and mostly redundant , CRM teams only needed updates daily. By shifting to daily batch syncs and optimizing the query to filter only changed records, they reduced warehouse costs by 60% ($300K+ annually) without impacting campaign performance. The insight: real-time isn’t always necessary. Understanding your use case determines both cost and effectiveness.
Use these levers to control cost:
- Query optimization: push filtering to the warehouse, not the tool
- Sync frequency: hourly vs. daily vs. on-demand based on actual use case
- Destination selectivity: sync to primary tools only, not every platform
Sync design: Reverse ETL requires clear definitions , what data matters, where it should go, and how often. Without this, syncs become noisy and inconsistent.
Volume and timing: Tools may charge based on destination count, number of synced rows, or audience size. Sync frequency also affects cost and performance. Choose timing based on real use cases.
Team readiness: Sales, lifecycle, and growth teams need processes to use the enriched data. Activation only works when downstream campaigns and workflows are set up to respond.
Organization Readiness Checklist
Before rolling out Reverse ETL, confirm you have:
- Data governance: clear ownership, documentation, and SLAs for key datasets
- Downstream workflows: sales, marketing, and success teams have playbooks for acting on enriched data
- BI/analytics capacity: someone owns sync monitoring and troubleshooting
- Compliance review: GDPR, CCPA, HIPAA alignment (if applicable)
- Measurement plan: defined success metrics (faster segmentation, higher conversion, lower churn)
Missing any of these? Address them before activation.
One client saved hundreds of thousands of dollars by adjusting the query timing and structure in their data warehouse. This required a refined understanding of their use-cases – specifically that real-time wasn’t vital for certain data sets – and generated significant savings without compromising ROI.
How Do You Get Started With Reverse ETL? (Timeline: 2–12 Weeks)
Week 1: Define Your Objective
Choose one high-impact use case: customer scoring, churn prediction, or lookalike audiences. Avoid activating everything at once.
Weeks 2–3: Map Your Architecture
Inventory your tools and data flows. Our free StackBuilder can help visualize your stack and highlight gaps between your warehouse and operational tools.
Weeks 4–6: Assess Data Maturity
Audit data quality: naming consistency, completeness, timeliness. Run a small pilot query to confirm clean outputs before syncing to downstream tools.
Weeks 6–8: Pilot With One Tool
Sync a cohort or audience to your primary tool , usually email or CRM. Measure impact: faster campaigns, higher targeting accuracy, reduced manual work.
Weeks 8–12: Expand and Operationalize
Add additional sync destinations. Establish SLAs, monitoring, and ownership. Document data definitions and refresh schedules for downstream teams.
Reverse ETL: Frequently Asked Questions
Is Reverse ETL the same as a CDP?
No. CDPs focus on ingesting data from many sources and resolving customer identity. Reverse ETL focuses on activation , moving modeled warehouse data into operational tools. Many companies use both: a CDP ingests and resolves, and Reverse ETL activates at scale.
How much does Reverse ETL cost?
It depends on tool and scale. Census and Hightouch charge based on destination row count and sync frequency. Custom pipelines carry engineering labor costs. Budget $10K–$100K+ annually depending on data volume and tool choice. ROI typically comes from reduced manual work and improved targeting accuracy.
What’s a typical implementation timeline?
Small pilots: 2–4 weeks (one use case, one tool). Full deployment: 2–3 months (multiple destinations, team enablement). The limiting factor is usually data maturity and downstream team readiness, not the tool setup.
Reverse ETL is not only a tool choice. It’s a capability that turns your warehouse from a reporting system into an operational engine. When done well, it powers better personalization, lifecycle marketing, attribution, and revenue performance.

Leave a Reply